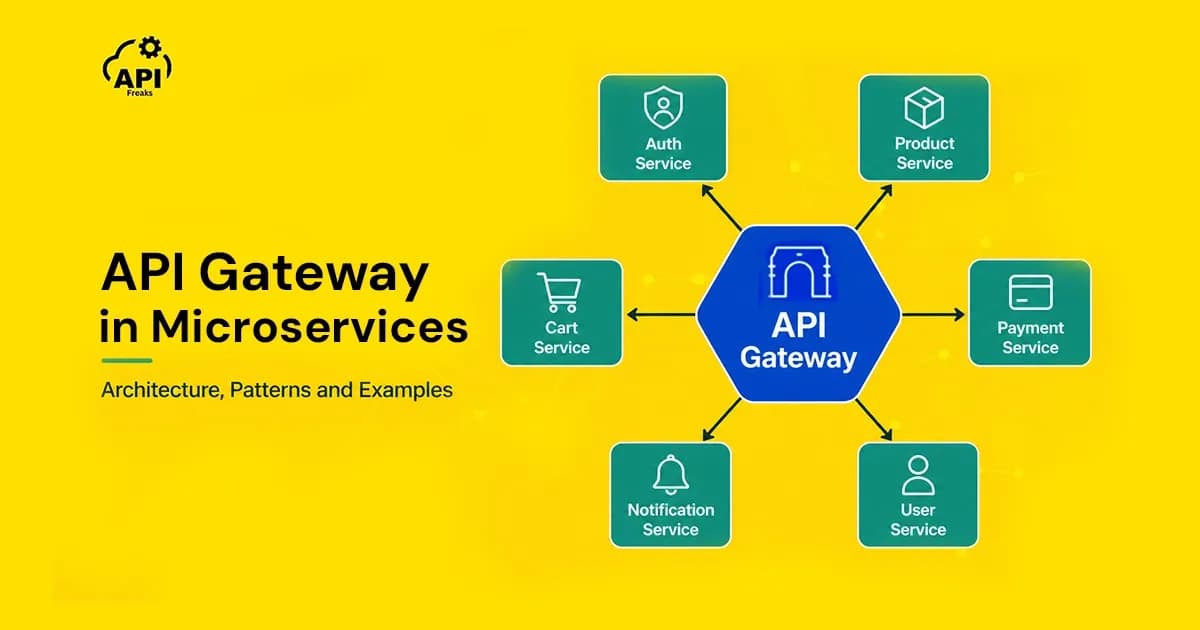
Modern software rarely lives in one place anymore. What used to be a single application handling everything from user login to payment processing has been broken apart into smaller, focused services that each do one thing well. This approach is called microservices architecture, and while it solves many problems, it creates a new one: how do client applications talk to all these services without things becoming a mess?
This guide is for software architects, backend developers, and technical leads who are designing or scaling microservices systems. Whether you're evaluating whether to adopt an API gateway, trying to choose between patterns, or looking for a solid reference to bring into a design review, this covers everything you need.
That is where the API gateway comes in. It acts as the single front door through which all client requests enter your system — quietly handling a long list of responsibilities so your individual microservices don't have to.
Key Takeaways
- An API gateway is the single entry point for all external client requests in a microservices architecture, handling routing, authentication, rate limiting, and more.
- Without an API gateway, clients must manage direct connections to every microservice — which becomes brittle and unmaintainable as the system scales.
- Common API gateway patterns include routing, aggregation, offloading, BFF (Backend for Frontend), transformation, circuit breaker, and security.
- API gateways and reverse proxies are different: a reverse proxy handles traffic forwarding, while an API gateway adds full API lifecycle management on top.
- Popular implementations include Kong, AWS API Gateway, Traefik, Envoy Proxy, Azure API Management, and Istio — each suited to different infrastructure contexts.
What are Microservices? A Quick Overview
A microservices architecture splits an application into small, independently deployable services — each owning a specific business capability and communicating over a network. Each service can be scaled, updated, or replaced without touching anything else.
A typical e-commerce platform built on microservices might have separate services for user authentication, product catalog, shopping cart, order processing, notifications, and payments. Each team can own and deploy their service on their own schedule.
This independence is powerful, but it introduces a coordination challenge. When a user loads their dashboard, client apps may need to coordinate with five different services simultaneously. If each service has its own URL, authentication mechanism, and response format, the client code becomes extremely complicated. That is exactly the problem an API gateway is designed to solve.
What are the Three Types of Microservices?
Microservices are commonly categorized into three types based on how they manage state:
- Stateless microservices — do not retain any session or user state between requests. The service processes each request independently. These are the easiest to scale horizontally.
- Stateful microservices — maintain state across requests, often backed by their own dedicated database or persistent storage. Examples include shopping cart services or user session managers.
- Actor-based microservices — use the actor model (as in Microsoft Orleans or Akka) to encapsulate state and behavior within discrete actors that communicate via message passing. Useful for high-concurrency scenarios like multiplayer games or real-time systems.
What are the 3 C's of Microservices?
The 3 C's — Communication, Consistency, and Coordination — represent the three core challenges that every microservices architecture must address.
Communication covers how services talk to each other: synchronously via REST or gRPC, or asynchronously via message queues like Kafka or RabbitMQ.
Consistency is the challenge of keeping data in sync across multiple services that each own their own database — distributed transactions and eventual consistency models both apply here.
Coordination refers to orchestrating workflows across services, managing failures gracefully, and ensuring the system as a whole behaves predictably even when individual services do not.
An API gateway addresses the communication challenge directly — it becomes the unified interface through which all client-to-microservice communication flows.
What is an API Gateway in Microservices?
An API gateway is a server that acts as the single entry point for all client requests in a microservices architecture. Instead of the client calling each microservice directly, every request goes to the gateway first. The gateway then authenticates the request, enforces policies, and forwards it to the right service.
Think of it like a hotel concierge. Guests don't wander through the kitchen, the laundry room, or the maintenance wing themselves. They tell the concierge what they need, and the concierge handles the rest. The API gateway works the same way: clients tell it what they want, and it coordinates with the right backend services to deliver a response.
Common responsibilities of an API gateway include: request routing, authentication and authorization, SSL termination, rate limiting, caching, request and response transformation, load balancing, centralized logging, request validation, and access control.
How an API Gateway is Structured
The client layer includes browsers, mobile apps, and third-party consumers. The gateway layer is the API gateway itself, handling all the cross-cutting concerns listed above. The services layer is the collection of backend microservices, each with its own logic and database.
The gateway maintains a routing table that maps incoming URL paths to internal service addresses. A request to /api/users gets forwarded to the User Service at an internal address, while /api/orders goes to the Order Service. This mapping is managed through configuration and can be updated without redeploying any services.
API Gateway vs Direct Client-to-Microservice Communication
Without an API gateway, clients must know the address of every microservice, maintain separate authentication logic per service, handle partial failures when one service is down, deal with different data formats from each service, and retrieve data from each service individually.
With an API gateway, the client only ever talks to one endpoint. The entire complexity of the backend is hidden. Services can be refactored, renamed, or replaced without the client needing to change a single line of code — as long as the gateway contract stays the same.
Is an API Gateway a Microservice?
An API gateway is not a microservice in the traditional sense — it does not encapsulate a specific business capability or own its own domain data. Rather, it is a cross-cutting infrastructure component that sits at the edge of your microservices system and manages how clients communicate with those services. If your gateway starts containing business logic, that is a design smell worth addressing.
How Does an API Gateway Work?
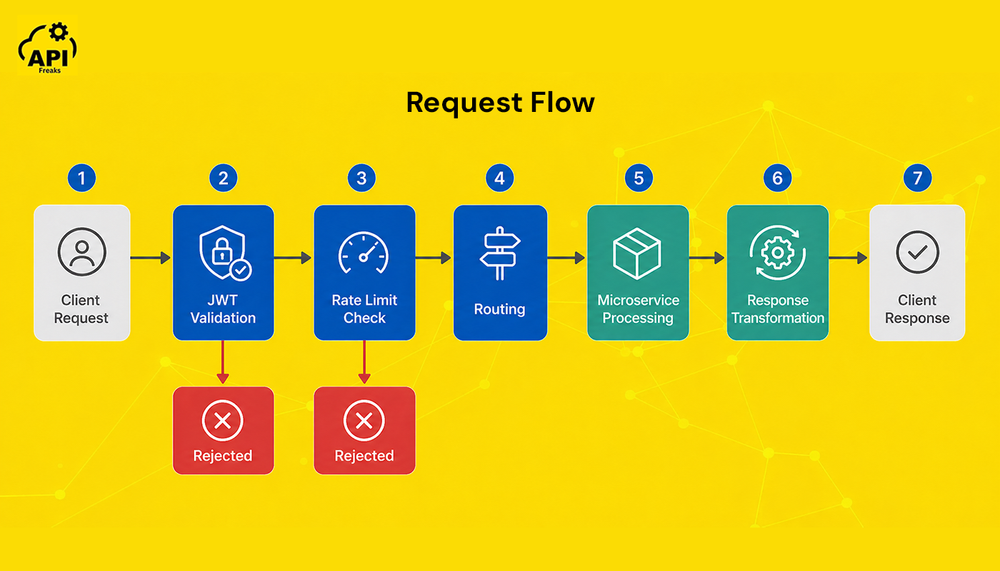
Here is what happens when a request passes through an API gateway:
- The client sends an HTTP or HTTPS request to the gateway endpoint.
- The gateway authenticates the request by verifying a JWT token, API key, or OAuth credential.
- Rate limiting checks confirm the client has not exceeded their allowed quota.
- The gateway consults its routing table and forwards the request to the appropriate microservice.
- The microservice processes the request and returns a response.
- The gateway may transform the response format before sending it back to the client.
- The final response is returned to the client.
In practice, steps 2 through 7 typically complete in under 10 milliseconds for a well-configured gateway — the overhead is real but rarely significant for most applications.
When multiple instances of a service are running, step 4 involves a load balancing decision. The gateway distributes traffic using one of three common algorithms: Round Robin (even distribution across instances), Least Connections (send to the least busy instance), or IP Hash (same client always hits the same instance, useful for session affinity). Most mature gateways let you configure this per route.
Common API Gateway Patterns
Over time, teams working with microservices have identified a set of recurring patterns for how the API gateway should be structured and used. Understanding these patterns helps you design a setup that fits your architecture rather than one that creates new problems. Each pattern addresses a specific type of complexity.
Gateway Routing Pattern
This is the foundation of every API gateway. The gateway acts as a reverse proxy, using the request path, headers, or query parameters to decide which backend service should handle the request. The client sends one request to one endpoint, and the gateway takes care of the rest.
This pattern is what allows you to completely restructure your backend services without breaking client integrations — as long as the public-facing routes stay consistent.
Gateway Aggregation Pattern
Sometimes a single page load requires data from multiple services at once. Rather than making the client fire off three separate API calls and stitch the responses together, the gateway calls all the relevant services internally, collects their responses, and returns a single combined payload.
For example, a user profile page might need account details from the User Service, recent orders from the Order Service, and loyalty points from the Rewards Service. The gateway calls all three in parallel and merges the results before responding. This significantly reduces the number of client-server round trips.
Gateway Offloading Pattern
Cross-cutting concerns like authentication, SSL termination, caching, and request logging don't need to be handled inside every microservice. With the offloading pattern, these responsibilities are moved to the gateway layer.
This is also where external validation APIs fit naturally. If you're doing IP-based access control or geo-blocking, the gateway is the right place to call an external IP geolocation API — not inside each individual service. Similarly, email or phone validation before routing a request to a downstream user service belongs at the gateway layer.
Each service then only needs to focus on its own business logic.
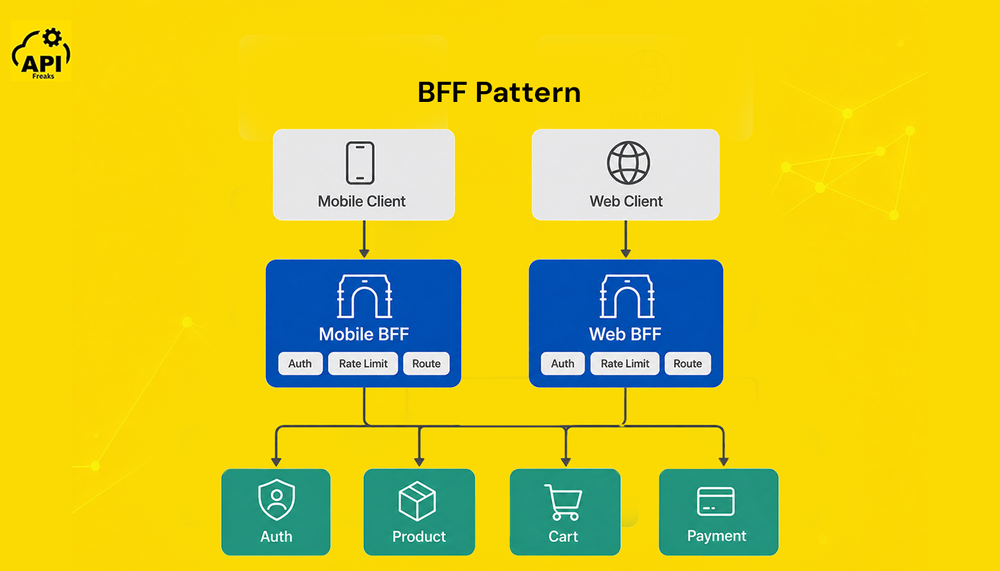
Backend for Frontend (BFF) Pattern
Different client surfaces have fundamentally different data needs. A mobile app on a slow cellular connection wants minimal payloads to conserve bandwidth. A desktop web app can afford richer, more complete responses in a single request. A TV or set-top device needs a response shaped for a 10-foot UI. Third-party API consumers add a fourth surface: they typically need versioned, stable contracts regardless of how internal services evolve underneath. The BFF pattern addresses this by deploying a separate gateway instance per client type, each tailored entirely to that surface's constraints and expectations.
Gateway Transformation Pattern
Not every service speaks the same protocol or data format — and not every client should need to know that. The transformation pattern gives the gateway responsibility for converting between formats as requests and responses pass through it.
In practice, this means the gateway might accept a REST/JSON request from a mobile client and forward it as a gRPC call to an internal service built to use Protocol Buffers. Or it might translate HTTP/1.1 requests to HTTP/2 to take advantage of multiplexing, or convert XML responses from a legacy service into JSON before returning them to modern clients. This lets you modernize backend services incrementally without breaking the client-facing contract.
Circuit Breaker Pattern
When a downstream service starts failing or responding slowly, continuing to send requests to it doesn't help — it makes things worse. The circuit breaker pattern is a protection mechanism that stops routing requests to a failing service for a defined period, giving it time to recover.
When a microservice starts returning errors above a threshold — say, 50% error rate in the last 10 seconds — the circuit breaker "opens," and subsequent requests fail fast without reaching the service. After a timeout it lets a small number of test requests through; if those succeed, normal traffic resumes.
Without a circuit breaker at the gateway layer, a single slow or failing service can exhaust the gateway's connection pool and cascade into a system-wide outage. Kong, AWS API Gateway, and Envoy all support circuit breaker configuration natively.
Gateway Security Pattern
The gateway is the natural enforcement point for system-wide security policies. Centralizing security at this layer means that individual services don't need to independently implement defenses that are better handled once.
WAF integration is one of the most impactful security additions. A Web Application Firewall at the gateway layer inspects incoming HTTP traffic and blocks malicious patterns before they reach any service. Common protections include SQL injection prevention (blocking requests with patterns like ' OR 1=1 --), cross-site scripting (XSS) defenses, and detection of oversized payloads that could indicate a denial-of-service attempt.
Beyond WAF, gateway-level security includes: DDoS mitigation through rate limiting and connection throttling, mTLS between the gateway and internal services to prevent lateral movement, API key validation with per-key rate limits, IP allowlisting and blocklisting, and geo-blocking using the client's IP address.
Types of API Gateway Deployments
How you deploy your API gateway is as important as which patterns you use. There are four main deployment models, each with different tradeoffs in complexity, scalability, and operational overhead.
Single API Gateway
A single, centralized gateway handles all external traffic for the entire system. This is the simplest model to start with and the most common starting point for teams adopting microservices. All routing rules, authentication policies, and rate limits are configured in one place.
The downside is that the single gateway can become a bottleneck as the system scales, and configuration complexity grows as more services are added. Teams often start here and evolve toward more distributed models as needs demand.
Microgateway (Dedicated Per Microservice)
In this model, each microservice (or each small group of related services) gets its own dedicated gateway instance. Rather than a central gateway managing all routing, each service exposes its own lightweight gateway that handles its own authentication, rate limiting, and policies.
This provides tighter control and isolation — a misconfiguration in one service's gateway doesn't affect others. It's more complex to manage, though, and requires good tooling (such as a control plane) to keep configurations consistent across many gateway instances. Kong's distributed model supports this approach well.
Per-Pod Gateway
In Kubernetes environments, a gateway can be deployed alongside each pod rather than as a standalone service. Each pod instance gets its own gateway co-located with it. This model is closely related to the sidecar pattern and is common in service mesh architectures.
The benefit is fine-grained traffic control at the pod level — you can apply different policies to different versions of a service during a canary deployment. The tradeoff is added resource consumption per pod.
Sidecar Gateway and Service Mesh
A sidecar gateway is a proxy deployed as a container alongside each service instance, intercepting all inbound and outbound traffic. When you deploy sidecar proxies across all services and connect them with a control plane, the result is a service mesh — an infrastructure layer that manages all service-to-service communication. Envoy Proxy is the most widely used sidecar; Istio uses Envoy and adds a control plane on top.
Deployment Type Comparison
Deployment Type | Complexity | Scalability | Best For | Example Tools |
|---|---|---|---|---|
Single API Gateway | Low | Moderate | Small to mid-scale systems, getting started | Kong, AWS API Gateway |
Microgateway | Medium | High | Teams that need per-service policy isolation | Kong, Tyk |
Per-Pod Gateway | High | Very high | Kubernetes environments, canary deployments | Envoy, Istio |
Sidecar / Service Mesh | High | Very high | Large-scale distributed systems, east-west traffic | Istio, Linkerd, Envoy |
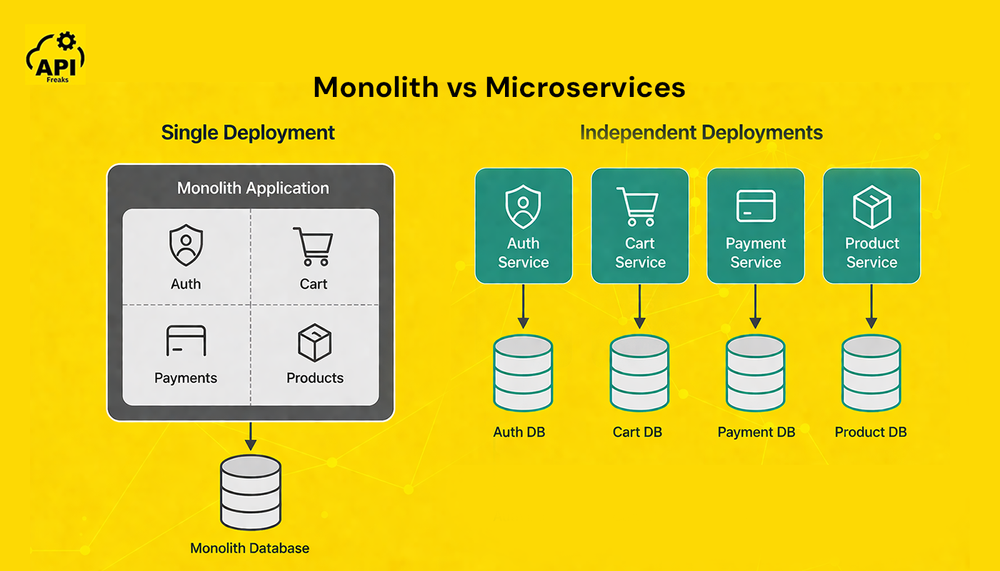
API Gateway in Monolithic vs Microservices Architecture
In a monolithic application, you don't need an API gateway. All the routing, security, and business logic live inside the same codebase — internal calls are function calls, not network requests. The application exposes a single backend API directly to clients, and adding a gateway in front of it would only introduce unnecessary complexity.
The picture changes completely once you move to microservices. Services are now separated by network boundaries. Each one has its own host, port, and potentially its own authentication mechanism. Without a gateway, a client application needs to know the address of every service it talks to, handle partial failures independently, and stitch together responses from multiple sources on its own. As the service count grows from 5 to 50, that becomes completely unworkable.
The API gateway is what makes a microservices system look like a single, coherent API to the outside world.
Dimension | Monolithic | Microservices with API Gateway |
|---|---|---|
Client communication | Direct to single backend | Single endpoint through gateway |
Security enforcement | Inside the application | Centralized at gateway layer |
Scaling | Everything scales together | Each service scales independently |
Deployment | Single deployable unit | Independent per service |
Real-World API Gateway Examples
Here is how Netflix, Amazon, and Uber implement these patterns in production systems.
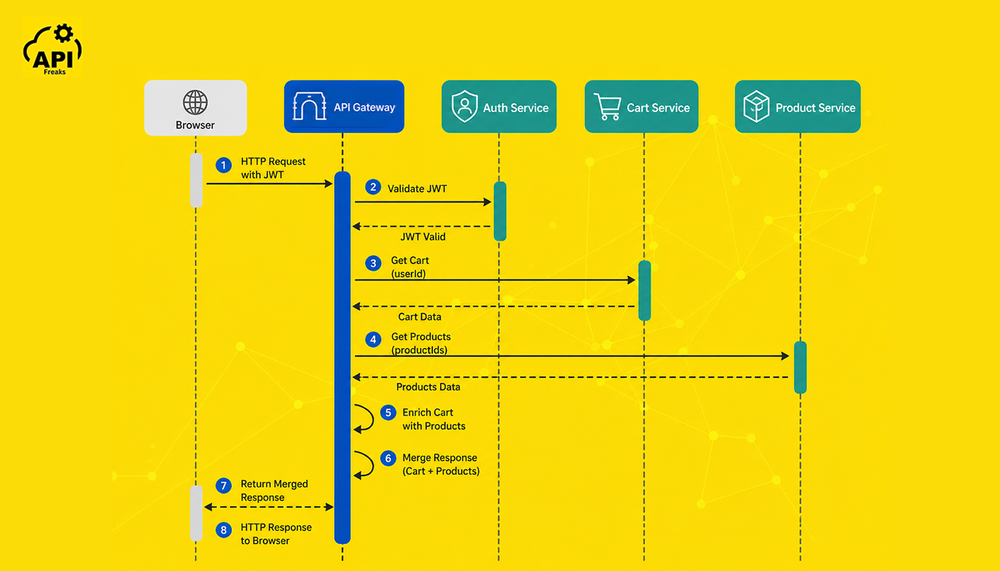
E-Commerce Cart: A Step-by-Step Walkthrough
Imagine an e-commerce platform with four microservices: Authentication, Product, Cart, and Payment. Here is how the API gateway handles a user request to view their shopping cart:
- The user's browser sends GET /api/cart with a JWT token in the Authorization header.
- The gateway validates the JWT against the Authentication Service.
- Rate limiting confirms this user has not exceeded their allowed requests per minute.
- The gateway forwards the request to the Cart Service at its internal address.
- The Cart Service returns a list of product IDs and quantities.
- Using the aggregation pattern, the gateway also calls the Product Service to enrich those IDs with names, images, and prices.
- The gateway merges both responses and returns a clean, combined payload to the browser.
In pseudocode, the gateway routing logic looks like this:
if (request.path === '/api/cart') {
const user = authenticate(request.headers.authorization);
const cart = await forward(request, 'http://cart-service:8080');
const products = await fetch('http://product-service:8081/batch', cart.productIds);
return merge(cart, products);
}
Netflix: BFF at Scale
Netflix runs separate gateway instances for different client surfaces — mobile, web, and TV devices — each returning response shapes optimized for that device. Mobile clients get compact payloads suited for limited bandwidth; desktop clients receive richer data structures. Client teams iterate independently without waiting on backend teams, because the gateway layer absorbs the differences.
Amazon: Aggregating Hundreds of Microservices
Amazon's product detail page is one of the most famous examples of microservices aggregation. The Amazon.com product page aggregates data from over 100 microservices to render a single page — product details, pricing, inventory, recommendations, seller information, and reviews all come from separate services. The gateway layer is what makes this seamless for the end user, who experiences a single page load rather than 100 API calls.
Uber: Gateway for Location and Routing Services
Uber's architecture uses API gateways to manage access to its high-throughput location and routing services. The company's real-time systems process millions of location updates per minute — the gateway layer enforces rate limits, routes requests to the correct regional service instances, and handles authentication for drivers and riders hitting the same underlying infrastructure through different clients.
Popular API Gateway Tools
Kong, AWS API Gateway, Traefik, Envoy Proxy, and Azure API Management are the most widely used API gateway tools today. Here is how to choose between them.
Tool | Type | Best For | Standout Feature |
|---|---|---|---|
AWS API Gateway | Cloud-managed | AWS-native applications | Native Lambda and IAM integration |
Kong | Open-source / Enterprise | High-traffic, plugin-heavy setups | Extensive plugin ecosystem |
NGINX | Open-source | Lightweight, high-concurrency proxying | Extremely fast and battle-tested |
Azure API Management | Cloud-managed | Azure-based architectures | Built-in developer portal |
Traefik | Open-source | Kubernetes and Docker environments | Automatic service discovery |
Apigee | Enterprise | Large organizations with complex APIs | Advanced analytics and monetization |
Envoy Proxy | Open-source | Service mesh, Kubernetes-native setups | Built for dynamic, high-scale environments |
Istio | Open-source (service mesh) | Full east-west + north-south traffic management | Integrates gateway and service mesh in one |
Ocelot | Open-source (.NET) | .NET and ASP.NET Core microservices | Native .NET integration, simple configuration |
Benefits of Using an API Gateway in Microservices
When used correctly, an API gateway delivers benefits that go well beyond simple request routing.
Centralized Security and Authentication
Security and auth logic live in one place — not duplicated across every service. This eliminates the risk of a misconfigured service accidentally exposing data, and it makes compliance audits significantly simpler.
Reduced Client Complexity and Round Trips
Clients talk to one stable endpoint regardless of how many services sit behind it. With the aggregation pattern, a client that previously made several separate service calls gets everything it needs in a single gateway request — directly reducing network overhead and page load time, particularly on mobile networks where each round trip adds noticeable latency.
Centralized Observability
Because all traffic flows through the gateway, you get one place to collect metrics, trace requests end-to-end, and set alerts. A single log pipeline replaces N separate ones across services, which reduces overhead and makes debugging dramatically faster.
Calling External APIs from Your Gateway Layer
The offloading pattern makes the gateway an ideal place to call external data APIs — rather than burdening individual business services with that responsibility.
If your system needs to validate email addresses before routing a registration request to the user service, that check belongs at the gateway. If you need to apply geo-based access rules, call an external IP geolocation API at the edge and make the routing decision there. This keeps each business service focused on what it does, and keeps external API calls centralized and auditable.
API Gateway vs Reverse Proxy: What is the Difference?
The two terms are often used interchangeably, but they are not the same thing. An API gateway typically includes reverse proxy functionality, but a reverse proxy does not include API gateway features.
A reverse proxy is a general-purpose server that forwards client requests to backend servers. It handles load balancing, SSL termination, and caching. It has no concept of API-specific concerns like authentication tokens, rate limiting per API key, or request transformation.
An API gateway is purpose-built for managing API traffic. It includes everything a reverse proxy does, plus a full layer of API management features: authentication, authorization, per-client rate limiting, request/response transformation, and detailed analytics.
API Gateway Trade-offs and Limitations
A fair evaluation includes the downsides. The API gateway pattern comes with trade-offs worth understanding before committing to it.
Single Point of Failure
All external traffic runs through the gateway, which means a gateway outage takes down all client access to your system. Running multiple gateway instances behind a load balancer is not optional for production environments — it is a requirement.
In production deployments, this means deploying at least two gateway instances in different availability zones, configuring health checks, and using a load balancer in front of the gateway instances. Cloud-managed gateways like AWS API Gateway handle this for you; self-hosted deployments need explicit planning.
Added Latency
Every request passes through one more network hop. For most well-configured deployments this overhead is negligible — typically a matter of milliseconds. For latency-critical systems — high-frequency trading, real-time gaming, sub-10ms SLA requirements — it is worth measuring before committing to a gateway architecture, potentially using a sidecar proxy model instead.
Configuration Complexity
A simple setup starts small, but as you add more services, routes, policies, and authentication rules, your team struggles to manage the configuration without proper tooling, version control, and documentation. In practice, teams managing Kong or AWS API Gateway at scale treat gateway config as infrastructure code — versioned in Git, reviewed in pull requests, deployed through CI/CD pipelines.
Conclusion
An API gateway is far more than a routing layer. It is the enforcement point for authentication, traffic control, observability, and security across your entire microservices system — and getting it right early saves enormous complexity later.
The patterns in this guide are not features to implement all at once. Routing is the foundation. Aggregation comes in when clients are making too many calls. The circuit breaker becomes critical once you have enough services that one failure can bring down the rest. BFF makes sense when different clients start pulling the API in different directions. Each pattern solves a specific problem — the mistake is adopting them before the problem exists.
What makes the gateway powerful is also what makes it worth careful planning. Every request in your system flows through it, which means a poorly configured or under-provisioned gateway becomes everyone's problem fast. Run multiple instances, treat the configuration as code, and monitor it like any other critical service.
Start simple, evolve deliberately, and let the architecture tell you when to add the next layer.
Frequently Asked Questions
What is the role of an API gateway in microservices?
The API gateway acts as the single entry point for all external client traffic in a microservices system. It handles routing, authentication, rate limiting, and other cross-cutting concerns centrally, so individual microservices can focus purely on their own business logic.
Is an API gateway necessary for microservices?
An API gateway is not strictly required, but it is strongly recommended for any production microservices system that serves external clients. Without a gateway, clients must manage direct connections to every service, which creates tight coupling, security inconsistencies, and a fragile client codebase that breaks every time a service changes.
What is the difference between an API gateway and a service mesh?
An API gateway handles north-south traffic — communication between external clients and your internal microservices. A service mesh manages east-west traffic — communication between internal microservices themselves. These address different challenges and are frequently used together in sophisticated architectures. A common pattern is to run Istio (or Linkerd) for internal service mesh traffic while running Kong or AWS API Gateway as the external-facing entry point.
What is the gateway design pattern?
The gateway design pattern refers to using a dedicated layer to control access from external consumers to a group of internal services. It encapsulates the backend structure, provides a clean and stable API to the outside world, and enables internal services to evolve independently without breaking client integrations.
Is an API gateway an architectural pattern?
Yes. An API gateway is both a software component and an architectural pattern. As a pattern, it belongs to the category of structural patterns for distributed systems. It defines a topology — a single entry point mediating access between clients and a collection of backend services — rather than a specific implementation. The same pattern can be implemented with Kong, AWS API Gateway, or any other tool.
What are the different types of API gateways?
API gateways are typically categorized by deployment model: a single centralized gateway, a microgateway deployed per service, a per-pod gateway in Kubernetes environments, and a sidecar gateway as part of a service mesh. They can also be categorized by management model: cloud-managed (AWS API Gateway, Azure API Management, Apigee) or self-hosted open-source (Kong, Traefik, Envoy).
What are the 3 C's of microservices?
The 3 C's of microservices are Communication, Consistency, and Coordination — covering how services exchange data, how data stays in sync across separate databases, and how multi-service workflows are orchestrated when things go wrong. The API gateway primarily addresses the communication challenge.
Can you use multiple API gateways?
Yes, and it is quite common. The Backend for Frontend pattern specifically recommends deploying separate gateways for different client types. Large organizations also often run separate gateways for public APIs, partner integrations, and internal tooling, each with their own policies and access controls. Netflix, Uber, and other large-scale systems use multiple gateway instances as a core part of their architecture.
What is the difference between a repository pattern and a gateway pattern?
These are different patterns that operate at different layers. The repository pattern is a data access pattern — it abstracts the details of how data is stored and retrieved, providing a clean interface for business logic to interact with a data store. The gateway pattern is a network access pattern — it abstracts how a client communicates with a group of external services. They both provide abstraction boundaries, but the repository pattern operates inside a single service, while the gateway pattern operates at the infrastructure boundary between clients and services.
What is the difference between a proxy and a gateway pattern?
A proxy pattern forwards requests on behalf of a client, typically without modifying them significantly. A gateway pattern is more opinionated — it enforces policies, transforms data, aggregates responses, and manages the full lifecycle of requests crossing a system boundary. A proxy is a mechanism; a gateway is a structured architectural pattern with defined responsibilities. In implementation, every API gateway includes proxy functionality, but a simple proxy is not an API gateway.